Publicado por Ralph Kimball en 2015
Archivado en Fundamentos diseño dimensional
Los modelos de datos dimensionales llevan aquí mucho tiempo. Ciertamente, casi podemos remontar sus orígenes al proyecto original Data Cube entre Dartmouth y General Mills a finales de 1960. El atractivo del modelado dimensional reside en la evidente simplicidad de los modelos y en la forma natural que la gente de negocios y la gente técnica puedan entender lo que significan estos modelos.
Los modelos dimensionales tienen dos expresiones diferentes, lógica y física. La expresión puramente lógica queda plasmada en el siguiente diagrama.
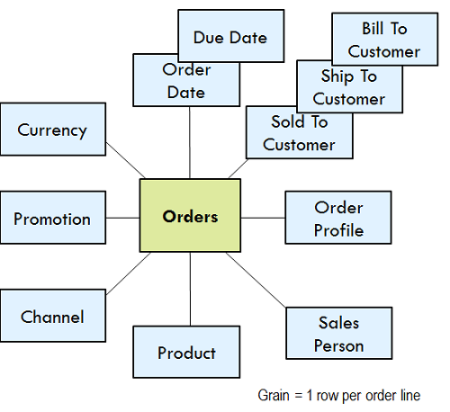
La caja del centro siempre representa mediciones de sucesos ("líneas de pedido" en el ejemplo). Llamamos a estos hechos. Las cajas de alrededor representan las dimensiones naturales asociadas con las mediciones del suceso. Hay poco contenido técnico de la base de datos en el diagrama del modelo lógico; pero mucho contenido de negocios. Una vez que la fuente de las mediciones de suceso ha sido identificada, el modelo lógico es el lugar donde empezar el diseño de forma seria.
Una vez aceptado, el diagrama del modelo lógico se transformará con bastante rapidez a un diseño técnico más específico repleto de nombres de tablas, nombres de campos, y declaraciones de claves primarias y foráneas. Esto es lo que piensan la mayoría de la gente IT de un modelo dimensional. Hmmm... esto parece muy físico. Cuando este diseño físico ha sido declarado, parece que el único paso que queda es escribir el DDL explícito creando las tablas objetivo, y después entrar en materia de implementar las conexiones ETL para rellenar los datos de estas tablas físicas.
Espera. ¡No tan rápido! Para ser honestos sobre este atractivo modelo físico dimensional, tenemos que admitir que en el nivel real de almacenamiento físico, nuestro modelo dimensional sería implementado de manera muy diferente. Los dos grandes "elefantes en la sala" son las bases de datos columnares y la virtualización de datos:
En lugar de atascarnos en argumentos religiosos sobre modelos lógicos versus físicos, debemos simplemente reconocer que un modelo dimensional es actualmente una interfaz de programación de aplicaciones (API) de data warehouse. El poder de esta API reside en la interfaz consistente y uniforme que ven todos los observadores, ambos usuarios y aplicaciones BI. Vemos que no importa donde están almacenados los bits o como se entregan cuando se lanza una solicitud desde la API.
El modelo dimensional API es muy específico. Debe exponer tablas de hechos, tablas dimensionales desnormalizadas y una columna para las claves subrogadas. La aplicación BI solicitante no puede y no debe ocuparse de cómo los grupos de resultados son implementados y entregados. Ahora vemos que la verdadera identidad del modelo dimensional es una API de data warehouse.

Artículo original: Kimball Group

Ralph Kimball es el fundador de Kimball Group y de Kimball University donde ha impartido clases sobre diseño de data warehouses a más de 10.000 estudiantes. Es el autor del best seller Data warehouse Toolkit. Ha dedicado 4 décadas diseñando sistemas DWH simples y rápidos.

